田中圭の復帰を“データで予測”する試み
芸能人の復帰は公式発表があるまで分からないものです。ファンとしては「いつ戻ってくるのか」「どんな作品で復帰するのか」と気になるところですが、確定情報がない以上、推測は難しい。
タナカーの妻を持つ私としては妻のメンタルのために少しでも情報は欲しいものです。
通常はXなどで情報取り入れますが今回はもっと客観的なデータを参考にします。
本記事では、Google Trendsの検索データを参考指標として扱い、田中圭さんの復帰の兆候を“見える化”する方法を紹介します。検索人気度の波をグラフ化することで、世間の関心が高まっているタイミングを把握し、復帰の可能性を考える材料にできるのです。
しかも、Google Colabを使えばインストール不要で誰でも簡単に試せます。この記事では、
- Colabで検索データを取得する方法
- 時間単位のデータを日単位にサンプリングする方法
- グラフ化して「話題の波」を直感的に理解する方法
を順を追って解説していきます。
💻 Google Colabとは?
「Google Colab(コラボ)」は、Googleが提供している無料のクラウド上のノートブック環境です。
- ブラウザさえあれば使える(インストール不要)
- Pythonというプログラミング言語を簡単に試せる
- データ分析やグラフ作成がすぐできる
- 無料で始められるので初心者にも安心
つまり「ちょっとしたデータ分析を試したい」「芸能人の検索トレンドを見てみたい」といったときに、誰でもすぐに使える便利なツールなんです。
タナカーなら、この記事のコードをコピー&ペーストするだけで「復帰の兆候を探る参考データ」を自分で作れるようになります。
📊 実践編:検索トレンドを可視化する
1. ライブラリの準備
まずはノートブックの新規作成から
必要なライブラリをインストールします。Colabのセルに以下を貼り付けて実行してください。
!pip install pytrends pandas matplotlib
2. データ取得(Google Trends)
次に、Google Trendsから「田中圭」の検索人気度を取得します。ここでは直近7日間、日本国内のデータを対象にします。
ちなみにキーワードを変更すると他の事にも使えます。
from pytrends.request import TrendReq
import pandas as pd
import matplotlib.pyplot as plt
# Google Trendsに接続
pytrends = TrendReq(hl='ja-JP', tz=540)
# キーワード設定
keywords = ["田中圭"]
# データ取得(過去7日間、日本)
pytrends.build_payload(keywords, timeframe='now 7-d', geo='JP')
# 検索トレンドデータを取得(時間単位)
data = pytrends.interest_over_time()
# 最新のデータ確認
print(data.tail())

👉 出力例
date 田中圭 isPartial
2025-12-12 08:00:00 33 False
2025-12-12 09:00:00 29 False
2025-12-12 10:00:00 32 False
2025-12-12 11:00:00 43 False
2025-12-12 12:00:00 40 True
3. 日単位にサンプリング
時間単位だと細かすぎるため、日ごとに平均化して「話題の波」を見やすくします。
# 日単位にリサンプリング(平均値)
daily_data = data.resample('D').mean()
# 日単位データを確認
print(daily_data.tail())
👉 出力例
date 田中圭 isPartial
2025-12-08 18.5 False
2025-12-09 22.0 False
2025-12-10 25.3 False
2025-12-11 30.1 False
2025-12-12 36.0 True
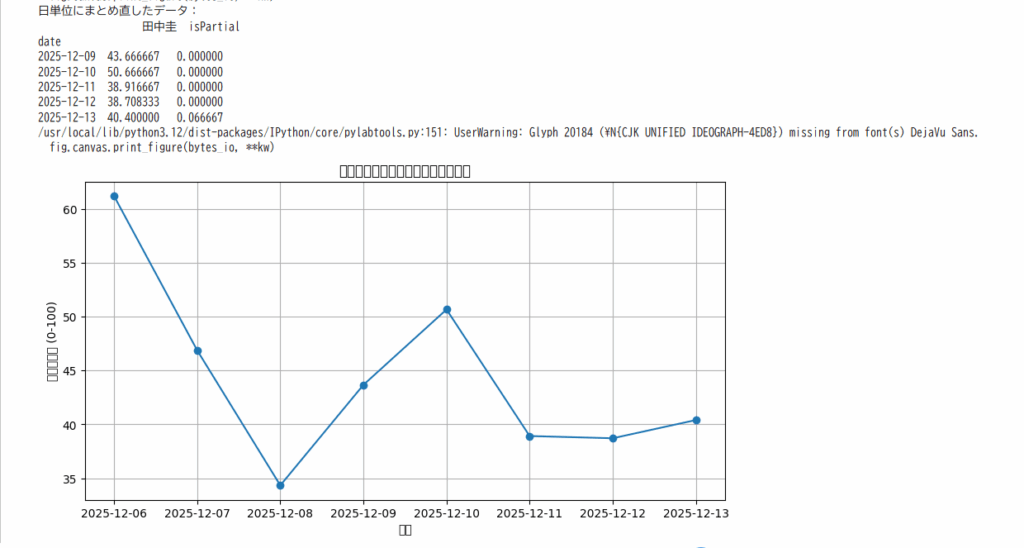
4. グラフ化(折れ線グラフ)
最後に折れ線グラフで可視化します。検索人気度の推移が一目でわかります。
plt.figure(figsize=(10,5))
plt.plot(daily_data.index, daily_data["田中圭"], marker='o', linestyle='-')
plt.title("田中圭の検索人気度(日単位平均)")
plt.xlabel("日付")
plt.ylabel("検索人気度 (0-100)")
plt.grid(True)
plt.show()
👉 出力イメージ
- 横軸:日付
- 縦軸:検索人気度(0〜100の相対スコア)
- 折れ線グラフで「話題が増えている日」「落ち着いている日」が直感的にわかる
こんな感じで出力されます
✅ ここまでのまとめ
- Colabならインストール不要で簡単にGoogle Trendsデータを扱える
- 時間単位データを日単位にサンプリングすることで「話題の波」を把握できる
- グラフ化すれば「復帰の兆候」を参考データとして見える化できる
復帰可能性スコアを作る
検索トレンドのグラフを見ても「話題が増えている」という傾向は分かりますが、ファンとしてはもう少し分かりやすい指標が欲しいところです。そこで、簡易的に「復帰可能性スコア」を設計してみましょう。
スコア設計の例
- Google Trendsで直近3日間の平均値が前週より 20%以上増加 → +10ポイント
- 「復帰」「主演」など関連ワードの検索が同時に増加 → +20ポイント
- 公式SNSで本人や事務所が発言 → +30ポイント
- ネガティブ報道(降板・休養延長など) → −40ポイント
👉 このように複数の要素を加点・減点していけば、毎週「復帰可能性スコア」を算出できます。
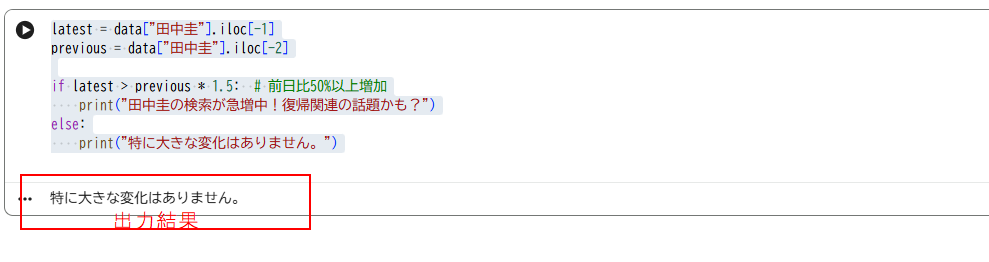
例
latest = data["田中圭"].iloc[-1]
previous = data["田中圭"].iloc[-2]
if latest > previous * 1.5: # 前日比50%以上増加
print("田中圭の検索が急増中!復帰関連の話題かも?")
else:
print("特に大きな変化はありません。")
まとめ
田中圭さんの復帰を断定することはできませんが、検索トレンドやSNSの動きを参考データとして見える化することは可能です。
Google Colabを使えば、初心者でも簡単にトレンドデータを取得し、日単位にサンプリングしてグラフ化できます。これにより「話題が高まっているタイミング」を直感的に把握でき、ファンとして復帰の兆候を楽しみながら追いかけることができます。
さらに「復帰可能性スコア」を設計すれば、毎週の変化を数値で表現でき、LINE通知Botやブログ記事に応用することで、日常的にチェックできる仕組みも作れます。
つまり、タナカーが自分の手で「復帰の兆しをデータで見える化する」ことができるのです。これは単なる予測ではなく、応援を続けるための新しい楽しみ方として活用できます。
📌 補足:相対スコアの見方と数値の意味
Google Trendsで表示される数値は「検索回数そのもの」ではなく、相対的な人気度スコアです。
- 0〜100の範囲で表示される
- その期間・地域で最も検索が多かった時点を「100」として基準化
- 他の時点はその比率で算出される
- 例
- ある週で「田中圭」の検索が最も多かった時間帯 → スコア100
- その時の検索数の半分だった時間帯 → スコア50
- 3分の1だった時間帯 → スコア33
- 注意点
- 実際の検索回数は公開されていない(絶対値は分からない)
- 同じ条件内(同じ期間・地域)での比較には有効
- 異なる期間や地域のスコアを直接比較することはできない
👉 つまり「数値が高いほど、その期間内で話題になっている度合いが強い」という意味になります。復帰の兆候を探る際には、急上昇や継続的な高スコアに注目するとよいでしょう。